《林老师带你学编程》 工作10年以上的一线大厂
🔥 具体的加入方式:
申明:本教程 IntelliJ IDEA 破解补丁、激活码均收集于网络,请勿商用,仅供个人学习使用,如有侵权,请联系作者删除。若条件允许,希望大家购买正版 !
PS: 本教程最新更新时间: 2024 年 2 月 14 日, 网站持续更新,收藏本站防失联哟 ~
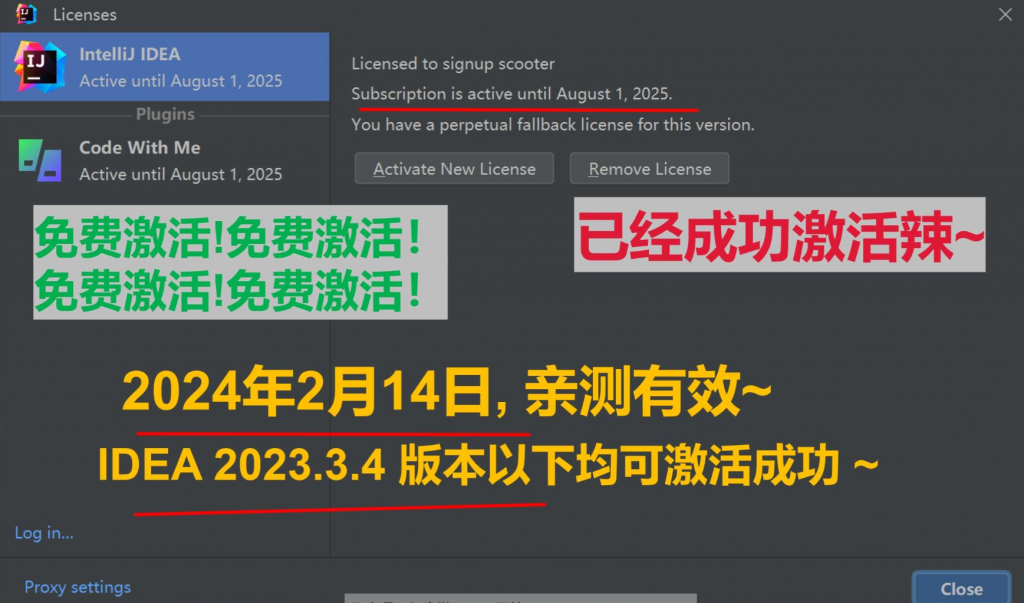
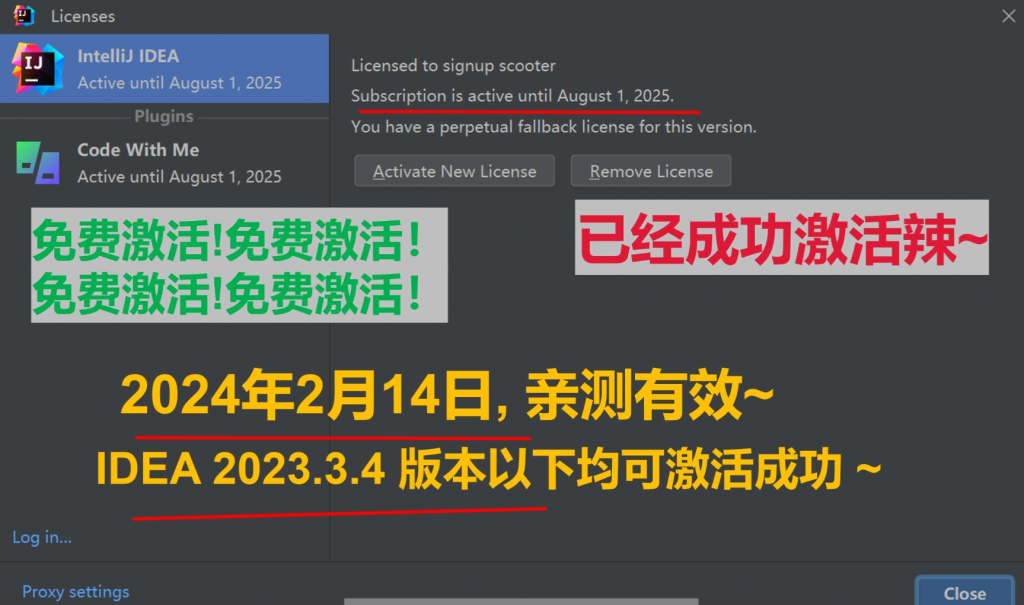
还在老家过年中,IDEA 就偷偷升级了一个小版本。又回到老话题,2023.3.4 这个版本是否还能破解,笔者也亲测了一下。还是沿用本站之前的破解方式,亲测依然有效,可以破解到 2025 年(实际是永久激活,只是这样会低调一些,防止被官方针对 ),无图无真相,下面是我破解成功的截图:
废话不多说,开始今天的IDEA破解教程~
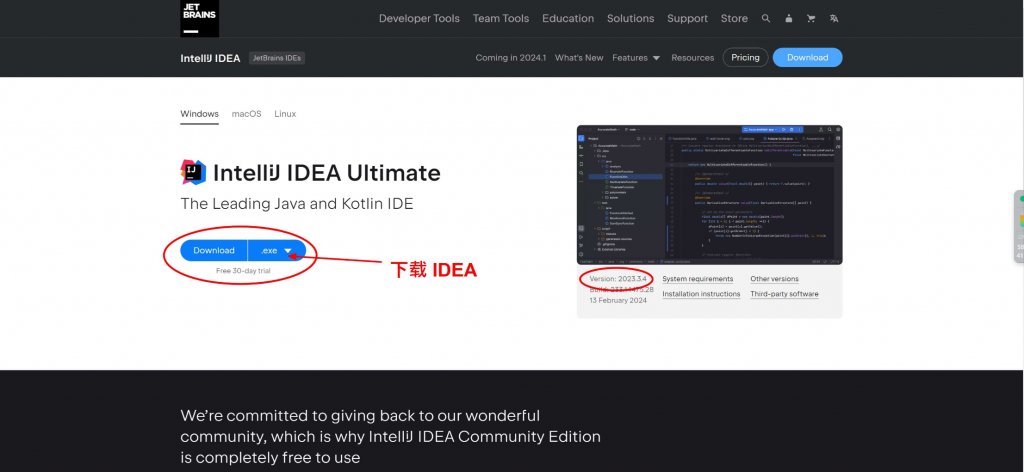
👉激活脚本 + 激活码(全自动模式) ,即本文教程所写,这种方法适合最新的几个版本,具体步骤跟着本文教程一步一步来,运行一下激活脚本,一分钟即可搞定,超级简单 。无图无真相,下面是我激活成功后的截图:本教程适用于 JetBrains 全系列产品,包括 IDEA、Pycharm、WebStorm、Phpstorm、Datagrip、RubyMine、CLion、AppCode 等。 本教程适用 Windows/Mac/Linux 系统,文中以 Windows 系统为例做讲解,其他系统同样参考着本教程来就行。 访问 IDEA 官网,下载 IDEA 2023.3.4 版本的安装包,下载链接如下 :
https://www.jetbrains.com/idea/download/
打开页面后,点击 Download 按钮, 等待 IDEA 专业版下载完毕。
注意,安装新版本 IDEA 之前,如果本机安装过老版本的 IDEA, 需要先彻底卸载,以免两者冲突,导致破解失败。
卸载完成后,点击 Close 按钮关闭弹框:
卸载老版本 IDEA 完成后,双击刚刚下载好的 IDEA 2023.3.4 版本安装包。弹框会提示选择安装路径,我这里直接选择的默认安装路径
C:\Program Files\JetBrains\IntelliJ IDEA 2023.3.4 , 然后点击 Next 按钮:
然后,勾选 Create Desktop Shortcut 创建 IDEA 桌面快捷启动方式,以方便后面快速打开 IDEA,再点击 Next 按钮 :
点击 Install 按钮,开始安装:
等待安装完成后,勾选 Run IntellJ IDEA, 点击 Finish 按钮即运行 IDEA :
IDEA 运行成功后,会弹出如下对号框,强制用户需要先登录 JetBrains 账户才能使用:
不用管登录的事,点击 Exit 按钮退出对话框 ,准备开始破解激活。
破解补丁我放置在了网盘中,提供了多个备用链接,以防下载失效。
提示:破解补丁的网盘链接文末获取 ~
提示:破解补丁的网盘链接文末获取 ~
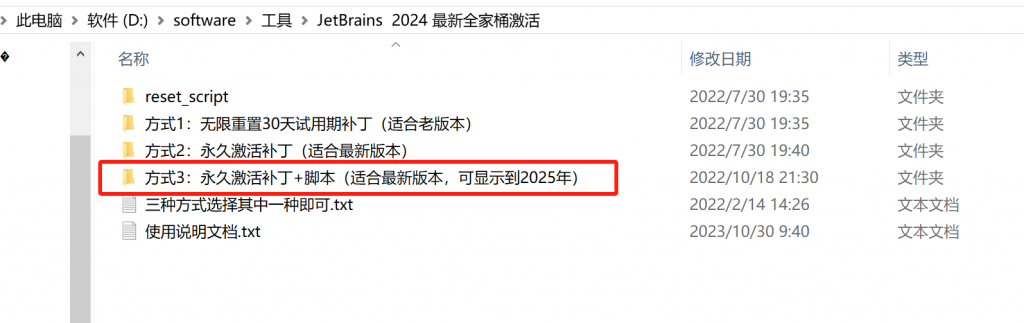
补丁下载成功后,记得先解压 , 解压后的目录如下, 本文后面所需补丁都在下面标注的这个文件夹中 :
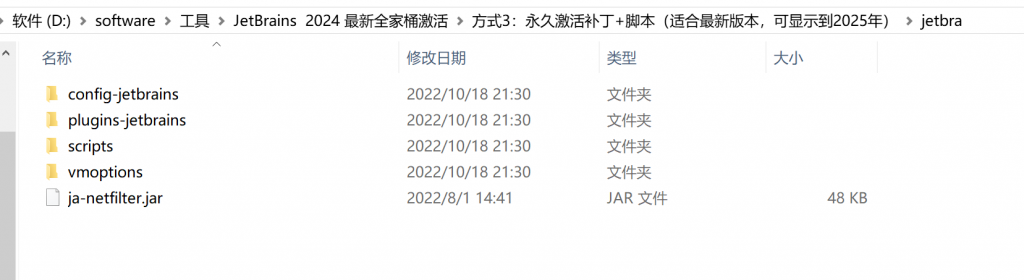
点击【方式 3】文件夹 , 进入到文件夹 /jetbra,目录如下:
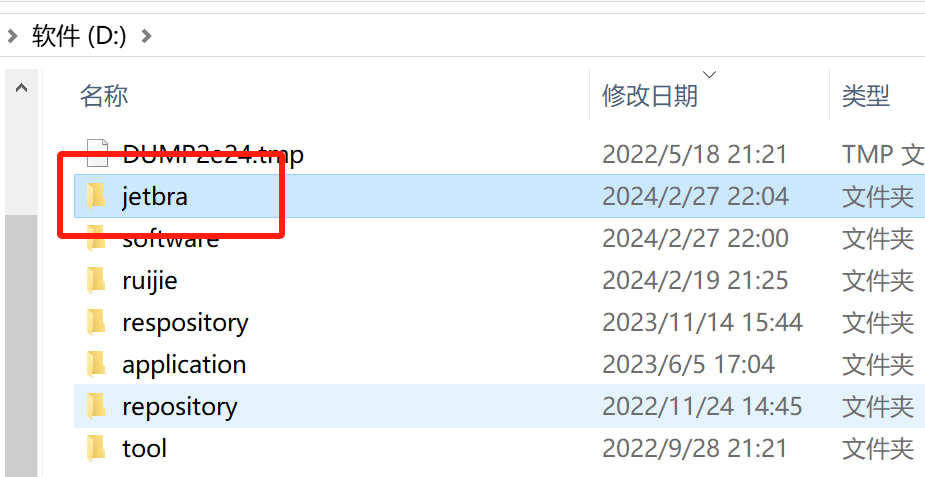
将上面图示的补丁的所属文件夹 /jetbra 复制电脑某个位置,笔者这里放置到了 D:/ 盘根目录下:
注意: 补丁所属文件夹需单独存放 ,且放置的路径不要有中文与空格 ,以免 IDEA 读取补丁错误。
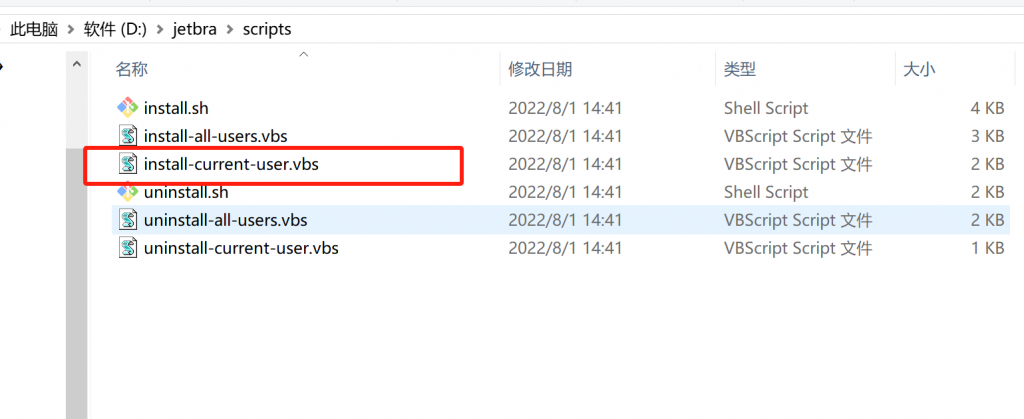
点击进入 /jetbra 补丁目录,再点击进入 /scripts 文件夹,双击执行 install-current-user.vbs 破解脚本:
注意:如果执行脚本被安全软件提示有风险拦截,允许执行即可。
会提示安装补丁需要等待数秒。点击【确定 】按钮后,过程大概 10 – 30 秒,如看到弹框提示 Done 时,表示激活破解成功:
Mac / Linux 系统与上面 Windows 系统一样,需将补丁所属文件 /jetbra 复制到某个路径,且路径不能包含空格与中文 。
之后,打开终端,进入到 /jetbra/scripts 文件夹, 执行 install.sh 脚本, 命令如下(因为需要修改环境变量,会提示需要输入电脑开机密码):
看到提示 Done , 表示激活成功。
如果提示:“Operation not permitted while System Integrity Protection is engaged ”,请先赋予权限,再重新执行。
部分小伙伴 Mac/Linux 系统执行脚本遇到如下错误:
解决方法:
可先执行如下命令,再执行脚本:
export LC_COLLATE='C'
export LC_CTYPE='C'
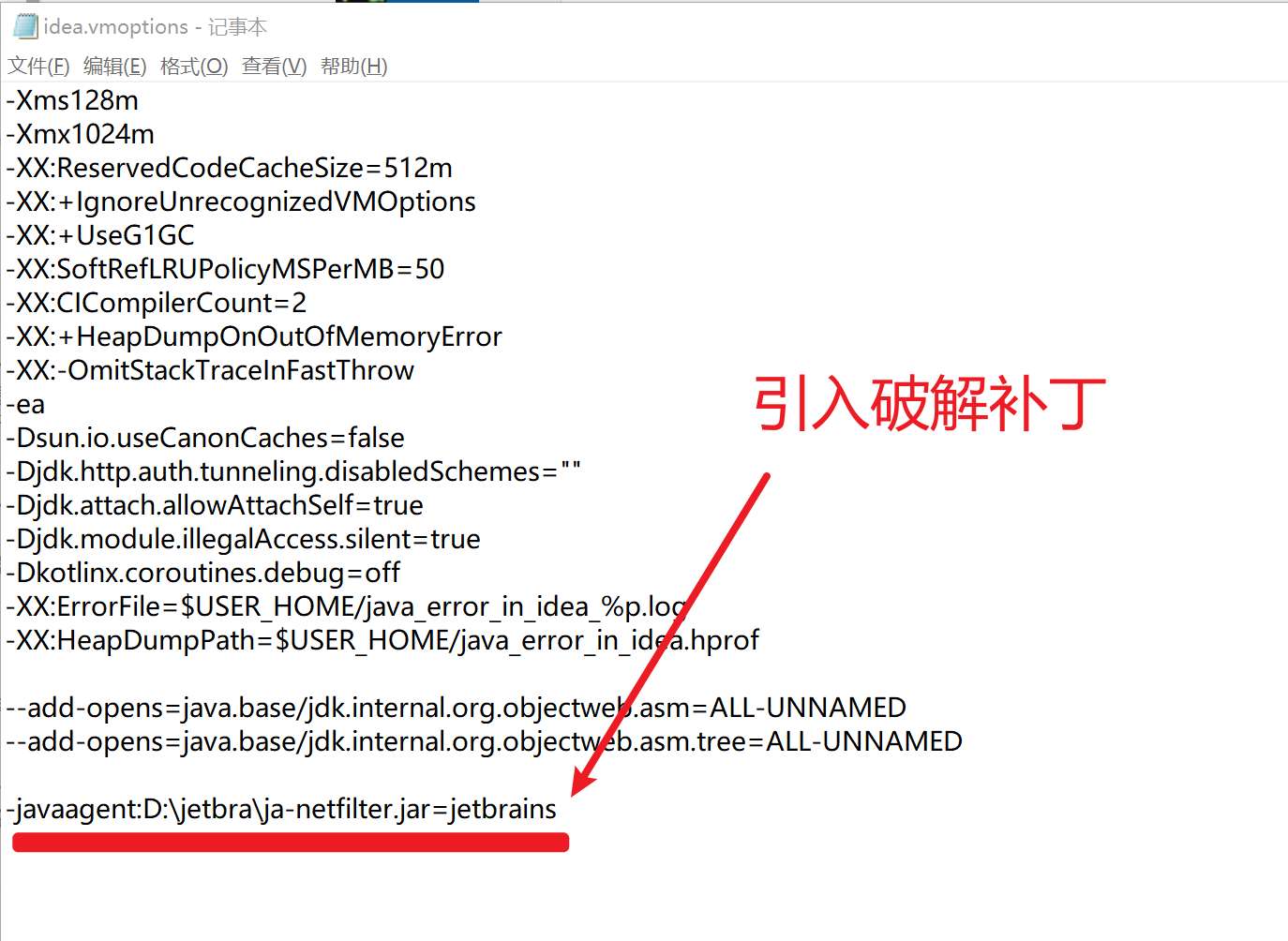
Windows 用户执行脚本后,脚本会自动在环境变量 -> 用户变量下添加了 IDEA_VM_OPTIONS 变量,变量值为 /jetbra 文件夹下的 .vmoptions 参数文件绝对路径,如下所示:idea.vmoptions 文件中引用了破解补丁 :提示: 细心的小伙伴应该也发现了,本文的破解方式与文章开头《第二种 IDEA 破解方法》的区别在于,这种方式提供了自动化脚本,脚本免去了手动引入补丁的繁琐步骤,一切都由脚本来完成了。 Mac / Linux 用户执行脚本后,脚本会自动在当期用户环境变量文件中添加了相关参数文件,Mac / Linux 需重启系统,以确保环境变量生效。 小伙伴们也可自行检查一下,如果没有自动添加这些参数,说明脚本执行没有成功。
脚本执行成功后,一定要重启 IDEA ~~
脚本执行成功后,一定要重启 IDEA ~~
重新打开 IDEA 后,复制下面的激活码:
6G5NXCPJZB-eyJsaWNlbnNlSWQiOiI2RzVOWENQSlpCIiwibGljZW5zZWVOYW1lIjoic2lnbnVwIHNjb290ZXIiLCJhc3NpZ25lZU5hbWUiOiIiLCJhc3NpZ25lZUVtYWlsIjoiIiwibGljZW5zZVJlc3RyaWN0aW9uIjoiIiwiY2hlY2tDb25jdXJyZW50VXNlIjpmYWxzZSwicHJvZHVjdHMiOlt7ImNvZGUiOiJQU0kiLCJmYWxsYmFja0RhdGUiOiIyMDI1LTA4LTAxIiwicGFpZFVwVG8iOiIyMDI1LTA4LTAxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlBEQiIsImZhbGxiYWNrRGF0ZSI6IjIwMjUtMDgtMDEiLCJwYWlkVXBUbyI6IjIwMjUtMDgtMDEiLCJleHRlbmRlZCI6dHJ1ZX0seyJjb2RlIjoiSUkiLCJmYWxsYmFja0RhdGUiOiIyMDI1LTA4LTAxIiwicGFpZFVwVG8iOiIyMDI1LTA4LTAxIiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJQUEMiLCJmYWxsYmFja0RhdGUiOiIyMDI1LTA4LTAxIiwicGFpZFVwVG8iOiIyMDI1LTA4LTAxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlBHTyIsImZhbGxiYWNrRGF0ZSI6IjIwMjUtMDgtMDEiLCJwYWlkVXBUbyI6IjIwMjUtMDgtMDEiLCJleHRlbmRlZCI6dHJ1ZX0seyJjb2RlIjoiUFNXIiwiZmFsbGJhY2tEYXRlIjoiMjAyNS0wOC0wMSIsInBhaWRVcFRvIjoiMjAyNS0wOC0wMSIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJQV1MiLCJmYWxsYmFja0RhdGUiOiIyMDI1LTA4LTAxIiwicGFpZFVwVG8iOiIyMDI1LTA4LTAxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlBQUyIsImZhbGxiYWNrRGF0ZSI6IjIwMjUtMDgtMDEiLCJwYWlkVXBUbyI6IjIwMjUtMDgtMDEiLCJleHRlbmRlZCI6dHJ1ZX0seyJjb2RlIjoiUFJCIiwiZmFsbGJhY2tEYXRlIjoiMjAyNS0wOC0wMSIsInBhaWRVcFRvIjoiMjAyNS0wOC0wMSIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJQQ1dNUCIsImZhbGxiYWNrRGF0ZSI6IjIwMjUtMDgtMDEiLCJwYWlkVXBUbyI6IjIwMjUtMDgtMDEiLCJleHRlbmRlZCI6dHJ1ZX1dLCJtZXRhZGF0YSI6IjAxMjAyMjA5MDJQU0FOMDAwMDA1IiwiaGFzaCI6IlRSSUFMOi0xMDc4MzkwNTY4IiwiZ3JhY2VQZXJpb2REYXlzIjo3LCJhdXRvUHJvbG9uZ2F0ZWQiOmZhbHNlLCJpc0F1dG9Qcm9sb25nYXRlZCI6ZmFsc2V9-SnRVlQQR1/9nxZ2AXsQ0seYwU5OjaiUMXrnQIIdNRvykzqQ0Q+vjXlmO7iAUwhwlsyfoMrLuvmLYwoD7fV8Mpz9Gs2gsTR8DfSHuAdvZlFENlIuFoIqyO8BneM9paD0yLxiqxy/WWuOqW6c1v9ubbfdT6z9UnzSUjPKlsjXfq9J2gcDALrv9E0RPTOZqKfnsg7PF0wNQ0/d00dy1k3zI+zJyTRpDxkCaGgijlY/LZ/wqd/kRfcbQuRzdJ/JXa3nj26rACqykKXaBH5thuvkTyySOpZwZMJVJyW7B7ro/hkFCljZug3K+bTw5VwySzJtDcQ9tDYuu0zSAeXrcv2qrOg==-MIIETDCCAjSgAwIBAgIBDTANBgkqhkiG9w0BAQsFADAYMRYwFAYDVQQDDA1KZXRQcm9maWxlIENBMB4XDTIwMTAxOTA5MDU1M1oXDTIyMTAyMTA5MDU1M1owHzEdMBsGA1UEAwwUcHJvZDJ5LWZyb20tMjAyMDEwMTkwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCUlaUFc1wf+CfY9wzFWEL2euKQ5nswqb57V8QZG7d7RoR6rwYUIXseTOAFq210oMEe++LCjzKDuqwDfsyhgDNTgZBPAaC4vUU2oy+XR+Fq8nBixWIsH668HeOnRK6RRhsr0rJzRB95aZ3EAPzBuQ2qPaNGm17pAX0Rd6MPRgjp75IWwI9eA6aMEdPQEVN7uyOtM5zSsjoj79Lbu1fjShOnQZuJcsV8tqnayeFkNzv2LTOlofU/Tbx502Ro073gGjoeRzNvrynAP03pL486P3KCAyiNPhDs2z8/COMrxRlZW5mfzo0xsK0dQGNH3UoG/9RVwHG4eS8LFpMTR9oetHZBAgMBAAGjgZkwgZYwCQYDVR0TBAIwADAdBgNVHQ4EFgQUJNoRIpb1hUHAk0foMSNM9MCEAv8wSAYDVR0jBEEwP4AUo562SGdCEjZBvW3gubSgUouX8bOhHKQaMBgxFjAUBgNVBAMMDUpldFByb2ZpbGUgQ0GCCQDSbLGDsoN54TATBgNVHSUEDDAKBggrBgEFBQcDATALBgNVHQ8EBAMCBaAwDQYJKoZIhvcNAQELBQADggIBABqRoNGxAQct9dQUFK8xqhiZaYPd30TlmCmSAaGJ0eBpvkVeqA2jGYhAQRqFiAlFC63JKvWvRZO1iRuWCEfUMkdqQ9VQPXziE/BlsOIgrL6RlJfuFcEZ8TK3syIfIGQZNCxYhLLUuet2HE6LJYPQ5c0jH4kDooRpcVZ4rBxNwddpctUO2te9UU5/FjhioZQsPvd92qOTsV+8Cyl2fvNhNKD1Uu9ff5AkVIQn4JU23ozdB/R5oUlebwaTE6WZNBs+TA/qPj+5/we9NH71WRB0hqUoLI2AKKyiPw++FtN4Su1vsdDlrAzDj9ILjpjJKA1ImuVcG329/WTYIKysZ1CWK3zATg9BeCUPAV1pQy8ToXOq+RSYen6winZ2OO93eyHv2Iw5kbn1dqfBw1BuTE29V2FJKicJSu8iEOpfoafwJISXmz1wnnWL3V/0NxTulfWsXugOoLfv0ZIBP1xH9kmf22jjQ2JiHhQZP7ZDsreRrOeIQ/c4yR8IQvMLfC0WKQqrHu5ZzXTH4NO3CwGWSlTY74kE91zXB5mwWAx1jig+UXYc2w4RkVhy0//lOmVya/PEepuuTTI4+UJwC7qbVlh5zfhj8oTNUXgN0AOc+Q0/WFPl1aw5VV/VrO8FCoB15lFVlpKaQ1Yh+DVU8ke+rt9Th0BCHXe0uZOEmH0nOnH/0onD
粘贴到输入框内,点击 Activate 按钮,就激活成功了。
PS: 有部分小伙伴反应,重启 IDEA 填入激活码依然无法激活,重启系统才行,如果有小伙伴遇到这种情况,不妨试试看 ~
激活成功后,又可以开心的 coding 了 ~
Key is invalid?输入激活码提示 key is invalid, 常见原因汇总到下面这篇文章了,可参考对照一下:
《JetBrains 产品输入激活码 Key is invalid 解决方案》
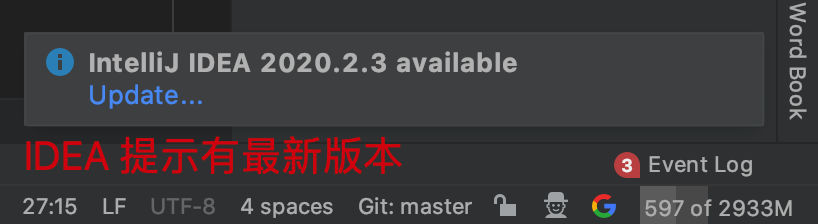
官方反制手段越来越严厉,这个版本能激活,新版本大概率补丁就被限制了。所以,如果打开 IDEA 后,右下角若出现提示升级新版本,请不要升级版本。能用就行,它不香嘛!
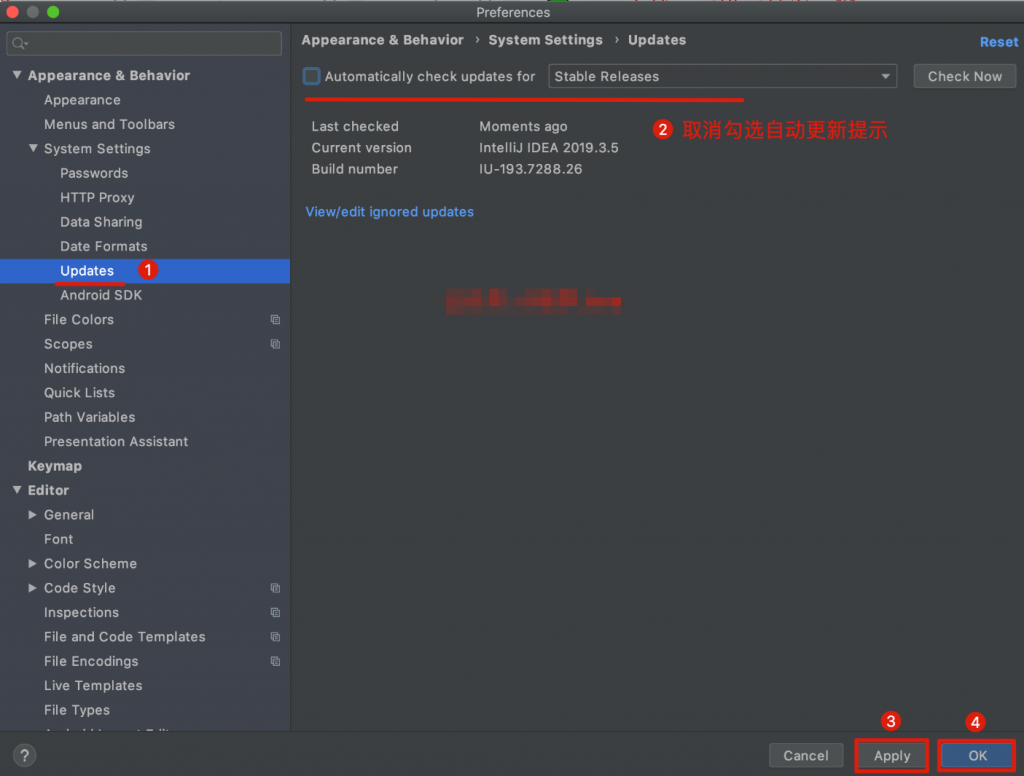
也可以手动关闭升级提示,这样就可以防止控制不住自己升级了,如何关闭,参考下面的文章:
👉《IntelliJ IDEA 如何关闭更新提示?》
上文中说到,执行脚本后会添加环境变量,变量值对应了你放置补丁位置的路径,删除掉或者移动,再打开 IDEA 就找不到对应文件了,激活也就失效了。放着吃灰就行,别动它。
PS: 破解补丁页面提取人数过多 ,导致分享的百度网盘链接容易被封 :改为从笔者公众号提取 。
需要的小伙伴,扫描下方公众号二维码 ,或者关注公众号 : 林老师带你学编程 ,回复关键字 :idea , 即可免费无套路获取激活码、破解补丁 ,持续更新中 ~。
本教程只做个人学习使用,请勿用于商业用途!


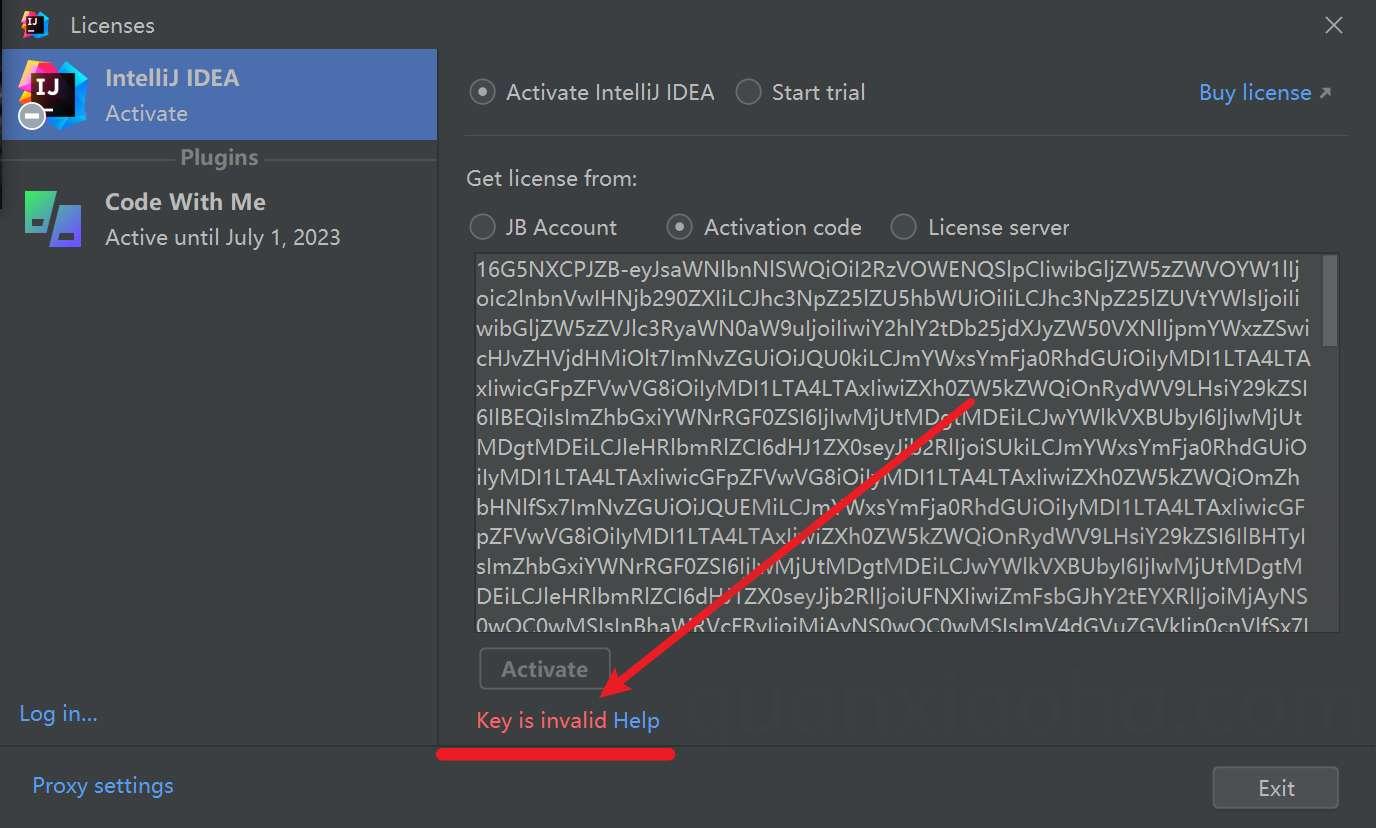 Jetbrains 产品输入激活码提示 key is invalid
Jetbrains 产品输入激活码提示 key is invalid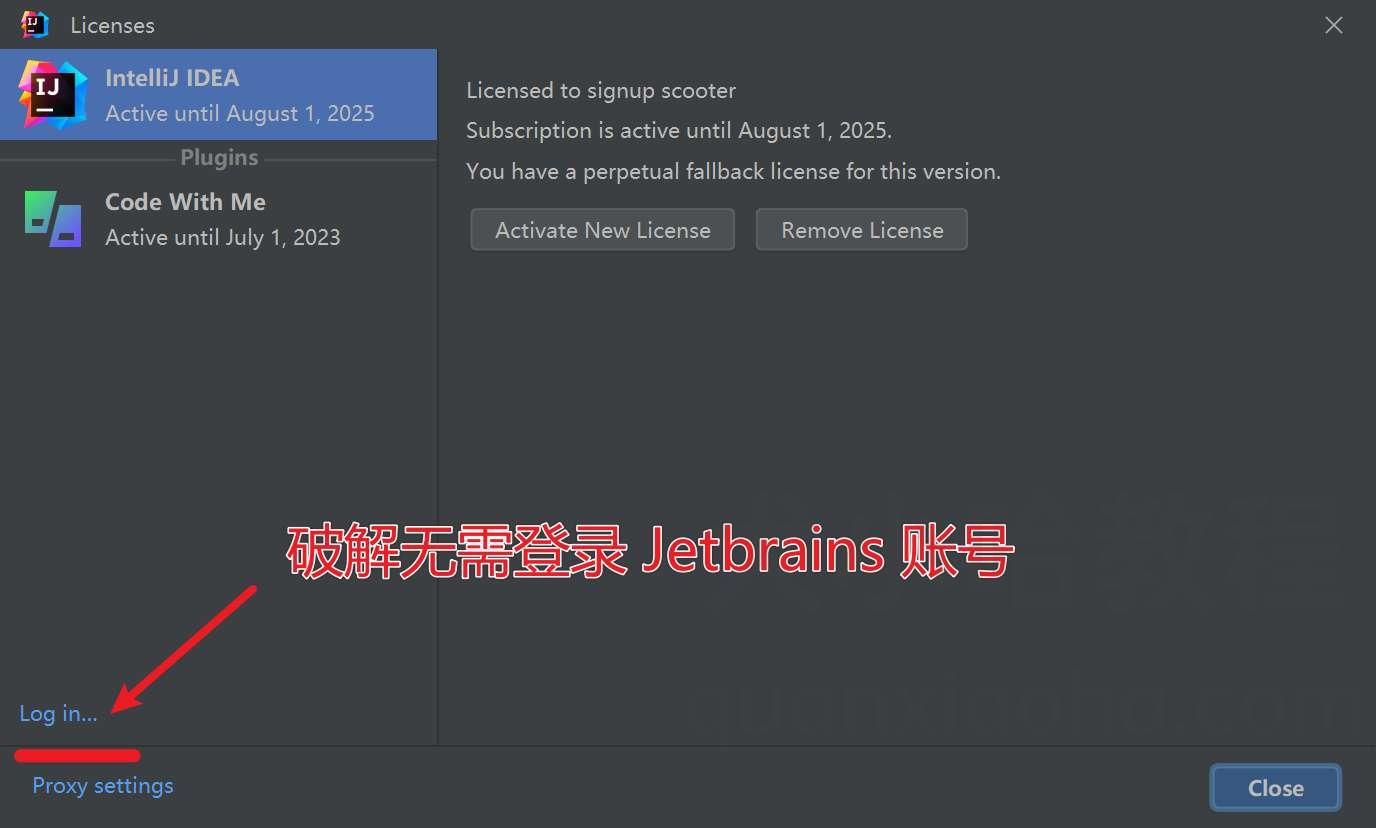 使用破解补丁,无需登录 JetBrains 账号
使用破解补丁,无需登录 JetBrains 账号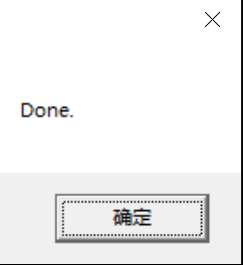 补丁执行成功后,提示 Done
补丁执行成功后,提示 Done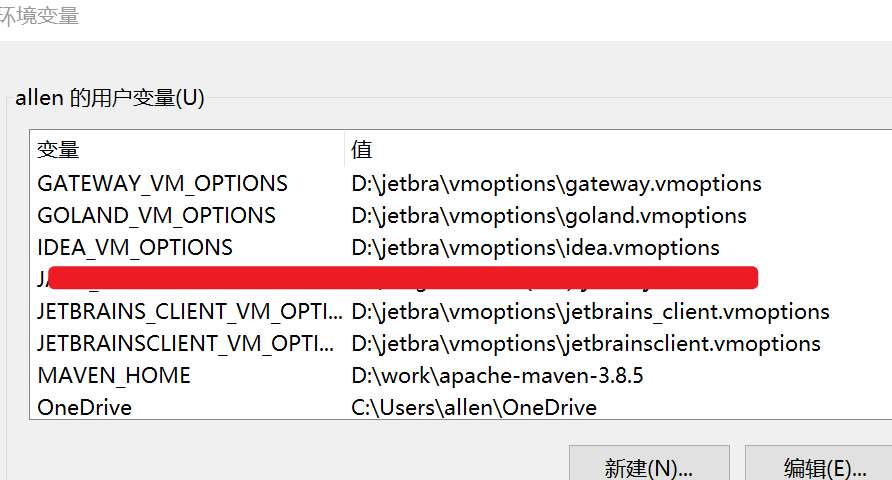















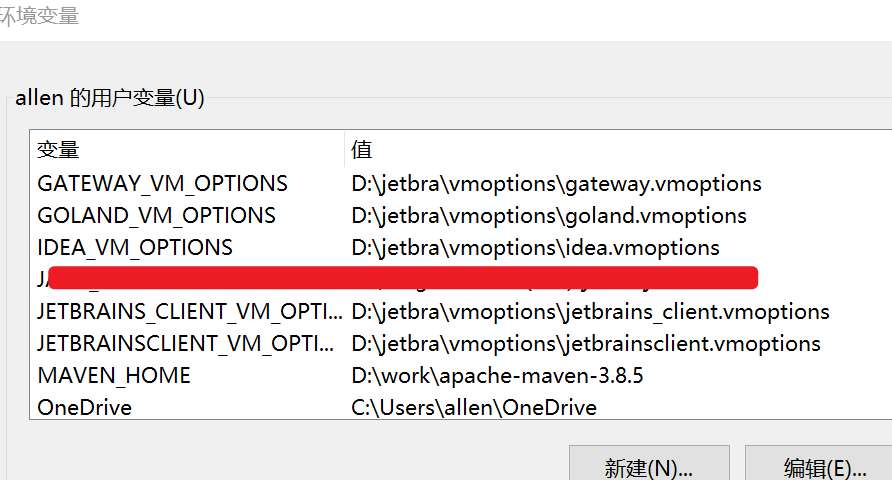 然后,脚本自动在
然后,脚本自动在 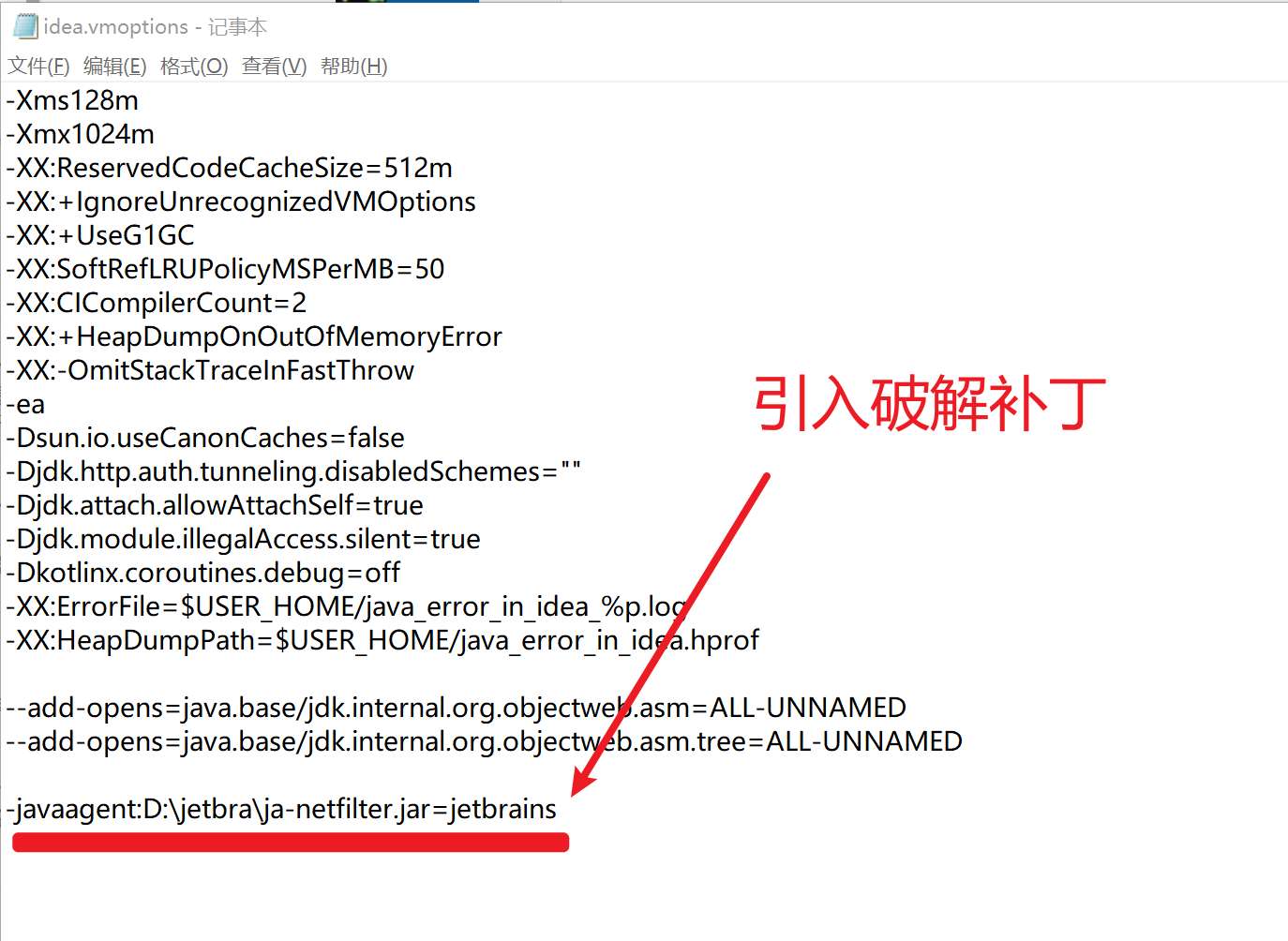 提示: 细心的小伙伴应该也发现了,本文的破解方式与文章开头《第二种 IDEA 破解方法》的区别在于,这种方式提供了自动化脚本,脚本免去了手动引入补丁的繁琐步骤,一切都由脚本来完成了。
提示: 细心的小伙伴应该也发现了,本文的破解方式与文章开头《第二种 IDEA 破解方法》的区别在于,这种方式提供了自动化脚本,脚本免去了手动引入补丁的繁琐步骤,一切都由脚本来完成了。

 蛋疼 ing,为限制人数,目前暂不提供页面直接提取,改为从笔者公众号提取。
蛋疼 ing,为限制人数,目前暂不提供页面直接提取,改为从笔者公众号提取。